Der Wandel der Suchmaschinen durch KI
Wie sich die Suche durch generative KI verändert
Suchmaschinen durchlaufen derzeit einen der größten Umbrüche seit ihrer Erfindung. Klassische Ergebnisseiten mit einer Liste blauer Links weichen zunehmend KI‑gestützten Antwortboxen, die vollständige Zusammenfassungen generieren. Google nennt diese neuen Ergebnisse AI Overviews, Microsoft spricht von Copilot-Antworten. Auch ChatGPT erzeugt über die Web-Browsing-Funktion eigene Zusammenfassungen aus öffentlich zugänglichen Webseiten.
Statt einzelne Links anzuzeigen, generieren diese Systeme komprimierte, kontextbezogene Antworten, oft mit eingebetteten Quellen. Sie beantworten Ihre Suchanfrage nicht nur – sie interpretieren sie. Das verändert sowohl das Informationsverhalten als auch die Anforderungen an Websites, die in Zukunft sichtbar bleiben möchten.
Quelle:
https://blog.google/products/search/generative-ai-google-search-may-2024
Generative Antworten: Was genau ist damit gemeint?
Mit „generativen Antworten“ meinen wir Antworten, die nicht direkt aus einer Quelle übernommen werden, sondern dynamisch von einem Sprachmodell (LLM) erzeugt werden. Diese Modelle analysieren mehrere Webseiten, erfassen deren semantische Inhalte und erstellen eine neue, zielgerichtete Antwort, die auf Ihre Suchintention zugeschnitten ist.
Es handelt sich nicht um klassische Zitate, sondern um synthetisierte Zusammenfassungen, die häufig um ergänzende Informationen erweitert werden.
Beispiele etablierter Systeme:
- Google Search (AI Overviews)
- Microsoft Bing mit Copilot
- ChatGPT (mit Browsing oder Plugins)
- Perplexity AI
- Brave AI Search
Warum Websites jetzt anders aufgebaut sein müssen
Im klassischen SEO genügte es lange, Inhalte sprachlich klar zu verfassen und technisch korrekt auszugeben. Im generativen KI‑Zeitalter ist das nicht mehr ausreichend. Ihre Inhalte müssen strukturierbar und maschinenverständlich sein, damit Sprachmodelle sie zuverlässig erkennen und generativ nutzen können.
LLMs bewerten Inhalte anhand ihrer Bedeutung, Relevanz und strukturellen Klarheit. Fehlende Struktur führt dazu, dass wertvolle Inhalte „untergehen“. Hier kommen strukturierte Daten ins Spiel – insbesondere das Schema-Vokabular von schema.org.
Was ist schema.org – und warum ist es für KI so wichtig?
Ursprung und Grundlagen von schema.org
schema.org wurde 2011 von Google, Bing und Yahoo gemeinsam gestartet, mit dem Ziel, Inhalte im Web einheitlich strukturieren und maschinenlesbar machen zu können. Yandex stieß kurz darauf als vierter Partner hinzu. Das offene Vokabular umfasst inzwischen über 800 Typen und mehrere tausend Eigenschaften. Websites können diese strukturierten Daten in verschiedenen Formaten einbinden. Die empfohlene Methode ist heute JSON‑LD, da sie sauber vom HTML getrennt ist und besonders gut von Suchmaschinen verarbeitet wird.
Rolle von schema.org in der heutigen AI‑SEO-Strategie
Strukturierte Daten sind längst kein reines SEO‑Detail mehr. Sie bilden die technische Grundlage dafür, dass Inhalte korrekt interpretiert und kontextbezogen verarbeitet werden können. Im KI‑Zeitalter, in dem Sprachmodelle Inhalte nicht nur crawlen, sondern verstehen und kombinieren, gewinnt schema.org massiv an Bedeutung. Studien und Marktanalysen zeigen, dass Webseiten mit sauber ausgezeichnetem Markup häufiger in KI‑generierten Antwortboxen erscheinen, insbesondere bei Google Search (AI Overviews), Bing mit Copilot oder in ChatGPT-Browsing-Ergebnissen.
Technische Funktionsweise von Vokabular und Datenmodell
schema.org basiert technisch auf einem flexiblen, semantischen Datenmodell. Es arbeitet mit Typen wie „Organization“, „Product“, „Person“ oder „Article“, die jeweils durch fest definierte Eigenschaften beschrieben werden. Diese Eigenschaften haben klare Regeln hinsichtlich ihrer Werte und ihrer Bedeutung. Die Datenstruktur ist hierarchisch aufgebaut, unterstützt Vererbung und lässt sich modular erweitern. Das JSON‑LD-Format ermöglicht es, strukturierte Daten im –Bereich oder direkt im Content-Bereich einzubinden, ohne den sichtbaren Code zu verändern. KI‑Systeme können diese Informationen auslesen und intern weiterverarbeiten, zum Beispiel in Retrieval-Systemen oder bei der Indexierung im Knowledge Graph.
Quellen:
Google Developer Docs zur Einführung in strukturierte Daten: https://developers.google.com/search/docs/appearance/structured-data/intro-structured-data
NP Group: „Role of Schema Markup in AI-Friendly Websites“ (2025): https://www.npgroup.net/blog/role-of-schema-markup-in-ai-friendly-websites
CMSWire: „The Growing Importance of Schema.org in the AI Era“ (Dezember 2024): https://www.cmswire.com/digital-experience/the-growing-importance-of-schemaorg-in-the-ai-era
schema.org Datenmodell-Dokumentation: https://schema.org/docs/datamodel.html
Wikipedia zu JSON-LD (Stand 22.07.2025): https://de.wikipedia.org/wiki/JSON-LD
Wie generative KI strukturierte Daten nutzt
Strukturierte Daten als Kontextgeber für LLMs
Generative KI‑Modelle wie GPT, Google Gemini oder Bing Copilot verwenden strukturierte Daten zur Verbesserung ihrer Antworten. Sie greifen beispielsweise auf Knowledge Graphs zurück, die aus schema.org‑Markup gespeist werden. Dieses Vokabular hilft KI‑Systemen, Inhalte besser zu identifizieren und Kontext herzustellen. So können Modelle spezifische Entitäten wie Personen, Orte und Produkte eindeutig erkennen, was zu präziseren, relevanteren Antworten führt.
Einsatz in Retrieval-Augmented Generation (RAG)
In RAG‑Systemen werden strukturierte Daten genutzt, um Dokumente gezielter zu durchsuchen und relevante Fakten präzise bereitzustellen. KI‑Systeme extrahieren strukturierte Informationen aus schema.org-Markup und ziehen damit Antworten direkt aus kuratierten Datenquellen. Das Resultat sind generierte Antworten, die zuverlässig mit realen Fakten unterlegt sind.
In diesem Video von IBM Technology wird das RAG-System genauer erklärt und zusätzlich mit "Fine Tuning" verglichen:
Einfluss auf Ergebnisdarstellung und Sichtbarkeit
Obwohl strukturierte Daten nicht direkt das Ranking beeinflussen, steigern sie die Wahrscheinlichkeit, in generativen Antwortboxen dargestellt zu werden. Google und Bing nutzen sie, um Rich-Snippets, FAQ-Boxen und Produktdetails in AI‑Übersichten einzubauen. Untersuchungen zeigen, dass Seiten mit sauber implementiertem schema.org‑Markup deutlich häufiger in generierten Antwortformaten erscheinen.
Quellen:
„Does Generative AI Use Structured Data for Results“, Stan Ventures, Feb 2025
„Role of Schema Markup in AI‑Ready Websites“, NP GROUP, Jan 2025
„The Semantic Value of Schema Markup in 2025“, SchemaApp, März 2025
„How Schema Markup Drives Success in AI‑Powered Search“, CMSWire, Dez 2024
„How Schema Supercharges Your Content for AI Search“, SEO Image, Jan 2025
Einfluss strukturierter Daten auf AI-Elemente in Suchsystemen
| schema.org-Typ | Genutzt in AI Overviews | Verwendet in Bing Copilot | Lesbar für ChatGPT-Browsing |
| Article | Ja | Ja | Ja |
| FAQPage | Ja | Teilweise | Ja |
| Product | Ja | Ja | Teilweise |
| Person/Author | Ja | Ja | Ja |
| Event | Teilweise | Teilweise | Gering |
JSON-LD Beispiel für "Article"
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "AI SEO mit schema.org: Strukturierte Daten als Schlüssel für generative Antworten",
"author": {
"@type": "Person",
"name": "Philip Frenz",
"sameAs": "https://www.linkedin.com/in/philip-frenz"
},
"datePublished": "2025-07-21",
"dateModified": "2025-07-21",
"publisher": {
"@type": "Organization",
"name": "Cyber Sour",
"logo": {
"@type": "ImageObject",
"url": "https://cyber-sour.com/logo.png"
}
},
"mainEntityOfPage": {
"@type": "WebPage",
"@id": "https://cyber-sour.com/blog/schema-org-generative-antworten"
}
}
</script>
Welche schema.org-Typen für KI besonders relevant sind
Artikel (Article)
Der Schema‑Typ Article spielt eine Schlüsselrolle für generative KI‑Systeme. Er liefert Metadaten wie Titel, Autor, Publikationsdatum, Hauptinhalt und Publisher‑Informationen. Diese Daten helfen KI‑Systemen, Artikel eindeutig zu identifizieren und in generativen Antworten korrekt zu referenzieren – beispielsweise bei AI Overviews oder ChatGPT‑Zusammenfassungen. Verschiedene Quellen bestätigen, dass Artikel‑Markup die Verwendung in generativen KI‑Antworten signifikant erleichtert.
Quellen:
https://whitepeak.io/what-is-schema-markup
https://www.cmswire.com/digital-experience/the-growing-importance-of-schemaorg-in-the-ai-era/
FAQs (FAQPage)
FAQ‑Seiten mit FAQPage‑Markup liefern Fragen und Antworten in einer strukturierten Form. Google empfiehlt dieses Format ausdrücklich für AI‑Usability und behält es weiterhin als eines der unterstützten Formate, selbst bei anderen kürzlich gestrichenen Typen. Studien zeigen, dass Seiten mit FAQPage‑Markup deutlich häufiger in generativen Antwortboxen auftauchen.
Quelle:
https://www.obilityb2b.com/blog/our-work/case-studies/schema-increases-rankings
Produkt, Organisation, Event und Person
Weitere wichtige Typen sind Product, Organization, Event und Person.
- Product‑Markup liefert Preis‑ und Verfügbarkeitsdaten, die in generativen Antworten, etwa Kaufempfehlungen, genutzt werden
- Organization und Person stärken EEAT‑Signale, die KI‑Systeme für Quellenbewertung nutzen
- Event‑Markup ist vor allem für ort- oder zeitgebundene KI‑Antworten relevant, etwa Terminübersichten
Quellen:
https://de.wikipedia.org/wiki/Generative_Engine_Optimization
https://www.enaks.io/post/best-practices-for-ranking-in-ai-generated-answers
https://www.brightedge.com/blog/structured-data-ai-search-era
Best Practices für schema.org im Kontext von AI SEO
Strukturierte Daten als fester Bestandteil jeder Inhaltsstrategie
Wenn Inhalte von generativen Systemen korrekt erfasst und verwendet werden sollen, müssen strukturierte Daten ein integraler Bestandteil der Content-Erstellung sein. Das betrifft nicht nur große Content-Portale, sondern auch kleinere Websites, Blogs oder Produktseiten. Empfehlenswert ist die direkte Einbindung von JSON-LD-Markup für alle zentralen Seitentypen insbesondere Article, FAQPage, Product, Organization und Person.
Sie sollten darauf achten, jede veröffentlichte Seite mit mindestens einem sinnvollen Typ zu versehen. Für Blogartikel bietet sich meist Article an, für Beratungsinhalte auch HowTo oder QAPage. Wichtig: Das Markup muss vollständig, syntaktisch korrekt und validierbar sein.
EEAT-Signale gezielt durch schema.org stärken
Die Rolle von EEAT (Expertise, Experience, Authoritativeness, Trustworthiness) hat sich durch generative KI noch weiter verstärkt. Sprachmodelle verwenden Informationen wie author, award, sameAs und worksFor, um die Vertrauenswürdigkeit einer Quelle besser einschätzen zu können.
Wenn Sie beispielsweise einen Fachartikel veröffentlichen, sollte der Autor im Markup mit vollständigem Namen, optional mit LinkedIn-Profil (sameAs) und der zugehörigen Organisation (worksFor) angegeben sein. Das stärkt sowohl das Vertrauen durch Nutzer als auch die Relevanz in KI-gestützten Antworten.
Technische Qualität und Validierung nicht vernachlässigen
Fehlerhafte oder unvollständige strukturierte Daten werden von KI-Systemen ignoriert oder falsch interpretiert. Deshalb ist es entscheidend, regelmäßig eine Validierung vorzunehmen, etwa mit dem Schema Markup Validator oder den integrierten Tools von RankMath, Yoast oder der Google Search Console.
Achten Sie auch darauf, dass keine widersprüchlichen Informationen zwischen sichtbarem Content und strukturierten Daten vorliegen. Konsistenz zwischen Inhalt und Markup erhöht die Wahrscheinlichkeit, dass Ihre Seite als Quelle in AI Overviews, Chatbots oder RAG-Systemen berücksichtigt wird.
Checkliste für schema.org im Kontext von AI SEO
Um Ihre Inhalte optimal für generative KI-Systeme vorzubereiten, sollten strukturierte Daten konsequent und strategisch eingesetzt werden. Die folgende Checkliste hilft Ihnen dabei, die wichtigsten Punkte für eine KI-optimierte Auszeichnung mit schema.org zuverlässig umzusetzen. Ideal zur Integration in Ihren Redaktions- oder Veröffentlichungsprozess.
JSON-LD als bevorzugtes Format verwenden
Nutzen Sie für die Auszeichnung strukturierter Daten das Format JSON-LD. Es ist am besten lesbar für Google, Bing und LLMs und trennt Markup vom sichtbaren HTML.
Passenden schema.org-Typ auswählen
Verwenden Sie für jede Seite einen relevanten Typ wie Article, FAQPage, Product, Person oder Organization. Achten Sie auf semantische Korrektheit.
EEAT-relevante Felder ergänzen
Tragen Sie nach Möglichkeit Felder wie author, sameAs, award oder worksFor ein. Diese stärken die Vertrauenswürdigkeit Ihrer Inhalte in KI-Systemen.
Markup mit den sichtbaren Inhalten abstimmen
Die strukturierten Daten sollten exakt das widerspiegeln, was auch im sichtbaren Content steht. Abweichungen können zu einer Nichtverwendung durch KI führen.
Validierung vor Veröffentlichung durchführen
Nutzen Sie den Schema Markup Validator oder Google’s Rich Results Test, um Fehler oder Warnungen zu identifizieren und das Markup technisch zu überprüfen.
Strukturierte Daten für jede Hauptseite integrieren
Binden Sie schema.org-Markup nicht nur auf der Startseite oder im Blog ein, sondern auch auf Leistungsseiten, Kategorieseiten, Landingpages und redaktionellen Artikeln.
Zukunftsausblick – Strukturierte Daten als Feed für LLMs
Von Indexierung zu Daten-Feeds
Suchmaschinen wie Google und Bing wandeln sich von reinen Link- und Dokumentindizes zu semantischen Datenverarbeitungssystemen. Die strukturierten Daten, die Sie heute als schema.org-Markup bereitstellen, könnten in Zukunft nicht mehr nur zur Darstellung von Snippets dienen, sondern direkt in LLMs eingespeist werden, etwa als Datenquelle in Retrieval-Augmented Generation (RAG) oder als Bestandteil von Knowledge Graphs.
Bereits heute gibt es Bestrebungen, Websites gezielt als Datenquelle für generative Systeme zu kuratieren. Google betont im Kontext von Search Labs, dass hochwertige Inhalte, die maschinenlesbar ausgezeichnet sind, bei AI Overviews bevorzugt behandelt werden.
Plugins, APIs und strukturierte APIs für LLMs
OpenAI, Microsoft und andere Anbieter experimentieren aktiv mit externen Datenquellen, die LLMs zur Laufzeit abfragen können. Bei OpenAI erfolgt dies über sogenannte Retrieval-Plugins oder eingebettete Tools in GPTs. Diese Systeme profitieren deutlich von strukturiertem, vordefiniertem Wissen, sei es über JSON-APIs, Linked-Data-Ressourcen oder klassische schema.org-Markups auf Websites.
Einige Unternehmen experimentieren bereits mit eigens gepflegten Content-Feeds im schema.org-Format, die regelmäßig aktualisiert und via API abgerufen werden können. Ziel ist es, generative Systeme nicht dem offenen Crawling zu überlassen, sondern kontrolliert mit semantisch strukturierten Inhalten zu versorgen.
Bedarf an neuen Vokabularen oder Weiterentwicklung von schema.org?
Ob schema.org ausreicht, um den wachsenden Anforderungen von LLMs gerecht zu werden, ist offen. Erste Vorschläge für neue Vokabular-Erweiterungen zielen auf Aspekte wie Quellenbewertung, Referenzierbarkeit und Nutzungsrechte ab. Auch Creative Commons diskutiert neue Ansätze, wie Inhalte eindeutig als vertrauenswürdige und maschinell nutzbare Ressource gekennzeichnet werden können.
Die Frage, ob künftig ein spezifisches KI-Vokabular entstehen muss oder schema.org flexibel genug bleibt, wird auch auf GitHub in der Community diskutiert. Der Trend geht aktuell eher zur modularen Erweiterung bestehender Strukturen.
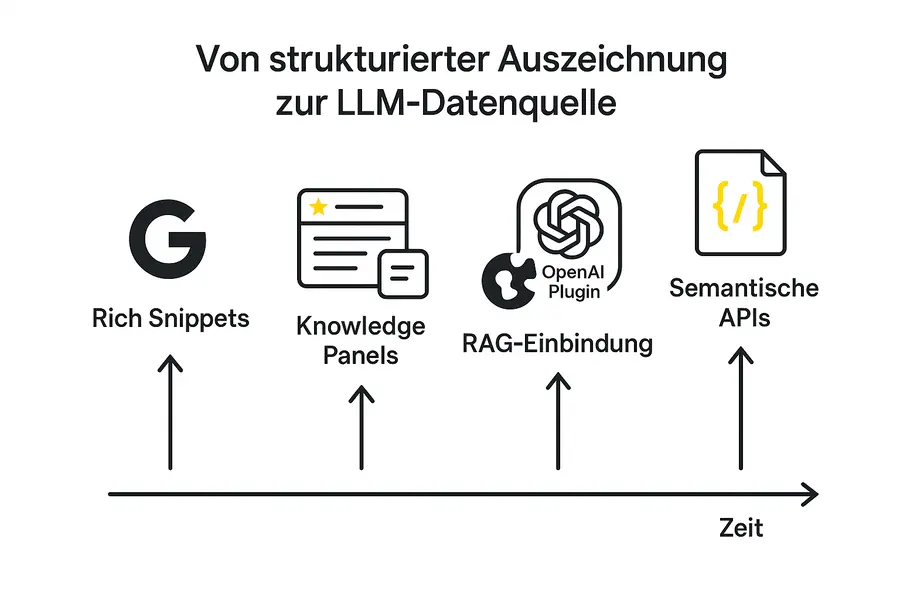
Fazit: Was strukturierte Daten im KI-Zeitalter leisten
Strukturierte Daten als strategischer Hebel für Sichtbarkeit
Die Zeiten, in denen schema.org-Markup primär zur Darstellung von Bewertungssternen oder FAQ-Boxen diente, sind vorbei. Heute entscheiden strukturierte Daten zunehmend darüber, ob Inhalte in generativen Antwortsystemen wie Google AI Overviews, Bing Copilot oder ChatGPT überhaupt noch vorkommen. Wer seine Inhalte nicht maschinenverständlich bereitstellt, riskiert, für LLMs unsichtbar zu bleiben, unabhängig davon, wie hochwertig der eigentliche Content ist.
Von SEO zu AI Visibility
Klassisches SEO bleibt wichtig, aber es muss erweitert werden: Die Lesbarkeit für Large Language Models wird zur neuen Basis digitaler Sichtbarkeit. Hier liegt ein großer Vorteil für alle, die bereits heute auf saubere, strukturierte Daten setzen. schema.org ist kein technisches Beiwerk mehr, sondern ein strategischer Schlüsselbegriff für moderne Content-Architektur.
Empfehlung für Unternehmen und Website-Betreiber
Wenn Sie nachhaltig Sichtbarkeit aufbauen möchten, sollten Sie Ihre Seiteninhalte systematisch mit strukturierten Daten versehen. Setzen Sie JSON-LD konsequent ein, wählen Sie passende schema.org-Typen und ergänzen Sie EEAT-relevante Eigenschaften. Prüfen Sie regelmäßig Ihre Auszeichnungen, validieren Sie das Markup und denken Sie langfristig: KI-Systeme werden zunehmend auf strukturierte, vertrauenswürdige Quellen zurückgreifen. Sorgen Sie dafür, dass Ihre Website dazugehört.
Häufig gestellte Fragen zu strukturierten Daten und schema.org - FAQ
Was sind Rich Text-Snippets von Google?
Rich Snippets sind erweiterte Suchergebnisse, die zusätzliche Informationen wie Bewertungen, Preise oder FAQs direkt in der Google-Suche anzeigen. Sie basieren auf strukturierten Daten wie schema.org.
Welche Rich Snippets gibt es?
Zu den häufigsten Rich Snippets gehören Bewertungssterne, Produktinformationen, FAQs, Rezepte, Veranstaltungen, Videos und Breadcrumbs. Sie verbessern die Darstellung in den Suchergebnissen deutlich.
Was sind strukturierte Daten?
Strukturierte Daten sind maschinenlesbare Informationen, die mit einem standardisierten Vokabular wie schema.org ausgezeichnet werden. Sie helfen Suchmaschinen, Inhalte besser zu verstehen und korrekt darzustellen.
Was sind strukturierte Daten in SEO?
Im SEO-Kontext sorgen strukturierte Daten dafür, dass Inhalte sichtbarer und verständlicher für Suchmaschinen werden. Sie erhöhen die Chance auf Rich Snippets und AI-generierte Antwortboxen.
Welche Beispiele gibt es für strukturierte Daten?
Beispiele sind Artikel mit Autor und Datum, Produkte mit Preis und Verfügbarkeit oder FAQs mit klarer Frage-Antwort-Struktur. Diese Informationen werden mithilfe von JSON-LD ausgezeichnet.
Was sind strukturierte Daten Beispiele?
Ein Blogartikel, der mit Article, author, headline und datePublished ausgezeichnet ist, ist ein typisches Beispiel. Ebenso ein Produkt mit Product, price und availability.
Welche Beispiele gibt es für Rich Snippets?
Typische Beispiele sind Bewertungssterne unter einem Produkt, FAQ-Akkordeons in der Suche, Rezeptinformationen mit Kochzeit oder Eventdaten mit Ort und Datum.
Wie wirken sich strukturierte Daten auf die Sichtbarkeit in AI Overviews aus?
Strukturierte Daten erleichtern generativen Systemen wie Google AI Overviews das Verständnis Ihrer Inhalte. Dadurch steigen die Chancen, mit konkreten Aussagen oder Zitaten in KI-Antworten aufzutauchen.
Welche schema.org-Typen sind für SEO besonders relevant?
Besonders relevant sind die Typen Article, FAQPage, Product, Person und Organization. Sie decken die wichtigsten Inhalte für redaktionelle Beiträge, Produktseiten und Unternehmensdarstellungen ab.
Wie kann ich strukturierte Daten mit WordPress einbinden?
Nutzen Sie Plugins wie RankMath oder Yoast SEO. Diese generieren automatisch strukturierte Daten im JSON-LD-Format und integrieren sie korrekt in den Code Ihrer Beiträge und Seiten.
Was ist der Unterschied zwischen strukturierten Daten und Meta-Tags?
Meta-Tags wie Title oder Description liefern Basisinformationen für die Suche. Strukturierte Daten hingegen beschreiben den Inhalt präzise und inhaltlich tiefer. Sie sind maschinenlesbar und semantisch aussagekräftiger.
Welche Tools helfen bei der Prüfung strukturierter Daten?
Empfohlen werden der Schema Markup Validator von schema.org, das Rich Results Tool von Google und integrierte Validatoren in SEO-Plugins wie RankMath oder Yoast.
Warum sind strukturierte Daten wichtig für generative KI?
Strukturierte Daten ermöglichen es Sprachmodellen wie ChatGPT oder Bing Copilot, Inhalte eindeutig zu erfassen und in Antworten einzuarbeiten. Ohne semantische Struktur ist dies deutlich schwieriger.
Können strukturierte Daten das Ranking verbessern?
Direkt beeinflussen sie das Ranking nicht. Indirekt steigern sie jedoch die Klickrate durch bessere Darstellung in den Suchergebnissen und fördern die Sichtbarkeit in AI-basierten Antwortformaten.
Was sind typische Fehler beim Einsatz von schema.org-Markup?
Zu den häufigsten Fehlern zählen falsche oder unvollständige Typangaben, fehlende Pflichtfelder, ungültige Syntax und Widersprüche zwischen sichtbarem Content und strukturiertem Markup.
Wie häufig sollte man strukturierte Daten aktualisieren?
Sobald sich Inhalte ändern, etwa Preise, Verfügbarkeit, Autor oder Veröffentlichungsdatum – sollten auch die strukturierten Daten entsprechend angepasst und validiert werden.
Können strukturierte Daten auch für Social Media genutzt werden?
Nicht direkt. Für Social Media gibt es eigene Formate wie Open Graph (Facebook) oder Twitter Cards. Strukturierte Daten sind primär für Suchmaschinen und KI-Systeme optimiert.