Sprachmodelle wie GPT-4, Claude oder Gemini verarbeiten täglich Milliarden von Texten – sie erkennen Muster, leiten Bedeutungen ab und generieren daraus Antworten, Empfehlungen oder sogar ganze Strategien. Doch was entscheidet eigentlich darüber, welche Inhalte ein Sprachmodell überhaupt versteht, einordnet und wiedergibt? Genau hier setzt der Begriff Content Signaling an.
In der klassischen Suchmaschinenoptimierung (SEO) sprechen wir häufig von Keywords, Backlinks und technischer Struktur. Diese Prinzipien gelten auch weiterhin – doch mit dem Aufstieg von LLMs verschieben sich die Anforderungen. Die Frage ist nicht mehr nur: Wie gut werde ich bei Google gefunden? Sondern auch: Wie gut werde ich in Sprachmodellen verstanden, zitiert oder weiterverwendet?
Wenn Unternehmen heute Inhalte veröffentlichen, reicht es nicht aus, sich ausschließlich an den Anforderungen von Suchalgorithmen zu orientieren. LLMs wie Gemini, ChatGPT oder Perplexity analysieren Texte anhand semantischer Signale, strukturierter Muster und kontextueller Zusammenhänge. Sie bewerten Inhalte nicht nur nach technischer Optimierung, sondern auch nach sprachlicher Klarheit, konzeptioneller Tiefe und logischer Kohärenz.
Ziel dieses Beitrags ist es, Ihnen Schritt für Schritt aufzuzeigen, wie Sie Ihre Inhalte so strukturieren, formulieren und bereitstellen, dass LLMs diese erkennen, korrekt einordnen und in ihren Antworten bevorzugt nutzen. Ich gehe dabei auf technische Grundlagen ein, erläutere zentrale Prinzipien des Content Signaling und liefere fundierte Empfehlungen für die Praxis.
Wie Sprachmodelle Texte verarbeiten
Wenn wir darüber sprechen, wie Inhalte für Sprachmodelle sichtbar und nutzbar werden, ist es wichtig zu verstehen, wie diese Modelle grundsätzlich funktionieren. In diesem Abschnitt zeige ich Ihnen, welche technischen Grundlagen hinter Large Language Models (LLMs) stehen und was es bedeutet, wenn ein LLM Inhalte „versteht“.
Die Rolle der Transformer-Architektur
Die technologische Basis moderner LLMs ist das sogenannte Transformer-Modell, vorgestellt 2017 durch Vaswani et al. im Paper „Attention Is All You Need“. Diese Architektur hat das klassische sequentielle Verarbeiten von Texten (wie bei RNNs) abgelöst. Stattdessen analysiert ein Transformer den gesamten Textkontext parallel – das Modell erkennt, welche Wörter in welchem Verhältnis zueinander stehen, ohne sie in einer festen Reihenfolge abarbeiten zu müssen.
Ein zentrales Konzept hierbei ist die Selbstaufmerksamkeit (Self-Attention). Das Modell „entscheidet“, welche Teile eines Textes besonders relevant sind, um die Bedeutung eines anderen Teils zu erfassen. So entsteht ein komplexes Netz von Relationen, das weit über reine Wortfolgen hinausgeht.
Quelle:
Vaswani et al. (2017), Attention Is All You Need: https://arxiv.org/abs/1706.03762
Trainingsdaten als Grundlage für Mustererkennung
LLMs lernen nicht durch Regeln oder Definitionen, sondern durch das Erkennen von statistischen Mustern in sehr großen Textmengen. Je mehr qualitativ hochwertige Inhalte ein Modell während des Trainings „sieht“, desto präziser kann es Sprachmuster, Fachbegriffe, Kontexte und semantische Verbindungen modellieren.
Das bedeutet: Inhalte, die bereits in großen, öffentlich verfügbaren Quellen enthalten sind (z. B. Wikipedia, öffentlich zugängliche Webartikel), haben eine höhere Wahrscheinlichkeit, im Modell repräsentiert zu sein. Inhalte, die nicht öffentlich zugänglich oder schlecht strukturiert sind, bleiben oft unsichtbar – unabhängig davon, wie relevant sie für ein Unternehmen oder eine Branche sein mögen.
Was bedeutet „Verstehen“ für ein Sprachmodell?
Anders als Menschen haben LLMs kein echtes Verständnis von Bedeutung im philosophischen oder kognitiven Sinn. Sie interpretieren keine Intentionen, haben kein Weltwissen im klassischen Sinn und können auch keine Wahrheit erkennen. Was ein LLM unter „Verstehen“ leistet, ist ein statistisch basiertes Erkennen von Mustern, Relationen und Wahrscheinlichkeiten.
Ein LLM „weiß“ also nicht, dass eine bestimmte Aussage wahr ist – es erkennt nur, dass ähnliche Aussagen in bestimmten Kontexten häufig miteinander auftreten. Das bedeutet auch: Inhalte, die klar, konsistent und semantisch gut eingebettet sind, werden wahrscheinlicher korrekt rekonstruiert oder weitergegeben als solche, die unpräzise, isoliert oder missverständlich formuliert sind.
Quelle:
Anthropic, The "think" tool: Enabling Claude to stop and think in complex tool use situations: https://www.anthropic.com/engineering/claude-think-tool

Was bedeutet Content Signaling im Kontext von LLMs?
Der Begriff Content Signaling beschreibt die Gesamtheit aller inhaltlichen, strukturellen und technischen Signale, die ein Text sendet, um für ein Sprachmodell verständlich, kontextualisierbar und nützlich zu sein. Während sich klassische SEO stark auf Sichtbarkeit in Suchmaschinen stützt, geht es beim Content Signaling darum, wie ein Inhalt intern verarbeitet und in das Wissensmodell eines LLMs eingebettet wird.
Abgrenzung zu klassischen SEO-Signalen
Viele Unternehmen optimieren ihre Inhalte nach wie vor primär für Suchmaschinen: Meta-Titel, Keyword-Dichte, Backlinks und strukturierte Daten sind nach wie vor wichtige Rankingfaktoren. Doch LLMs arbeiten anders – sie bewerten Inhalte nicht auf Basis von Click-Through-Rates oder SERP-Positionen, sondern anhand von semantischen Mustern und Kohärenz im Kontext.
LLMs „lesen“ also Texte nicht mit einem Ziel wie „Rank besser“, sondern erkennen, welche Aussagen logisch konsistent, thematisch eingebettet und sprachlich sauber strukturiert sind. Dabei fließen auch implizite Signale wie Argumentationsführung, Quellenlage oder thematische Verortung mit ein – unabhängig davon, ob der Text SEO-optimiert ist oder nicht.
Warum Content Signaling für LLMs wichtig ist
Ein Sprachmodell erstellt bei jeder Trainingsiteration und auch bei der Inferenz sogenannte Repräsentationen von Inhalten – in Form von Vektoren, die sich im semantischen Raum zueinander verhalten. Inhalte mit klaren Signalen – etwa durch präzise Begriffe, logische Struktur oder gut eingebettete Fachkonzepte – lassen sich stabil und eindeutig positionieren.
Das hat direkte Auswirkungen auf die Nutzbarkeit:
- Inhalte mit starkem Signaling erscheinen häufiger in Antworten.
- Sie werden präziser zitiert oder paraphrasiert.
- Ihre Bedeutung bleibt in unterschiedlichen Prompt-Kontexten stabil.
Wenn ein Text dagegen unscharf formuliert, isoliert oder schlecht eingebettet ist, kann er vom Modell entweder ignoriert oder falsch kontextualisiert werden – mit potenziell gravierenden Folgen für Reputation, Auffindbarkeit und Reichweite.
Quellen:
Google Research Blog: https://ai.googleblog.com
Ethan Mollick (Wharton), „How LLMs interpret the web“: https://www.oneusefulthing.org
Eine kurze, grafische Zusammenfassung:
| Aspekt | Klassisches SEO | Content Signaling für LLMs |
| Ziel | Sichtbarkeit in oberen Positionen in den Suchergebnissen | Einordnung und Repräsentation im Modell |
| Relevanzbewertung | CTR, Backlinks, On-Page-Faktoren | Kontext, Semantik, Klarheit |
| Strukturfokus | HTML-Optimierung, Meta-Daten | Semantische Tiefe, logische Argumentation |
| Verarbeitung | Indexierung durch Crawler | Einbettung in Vektorräume (Embeddings) |
| Effekt | Höheres Ranking bei Suchanfragen | Höhere Wahrscheinlichkeit, in Antworten zu erscheinen |
| Technischer Fokus | Keyword-Dichte, Title, URL-Struktur | Bedeutungsnetzwerke, Signalstärke |
Welche Signale LLMs in Inhalten erkennen – und wie man sie steuert
Content Signaling ist kein einzelnes technisches Feature, sondern eine Zusammensetzung aus sprachlichen, strukturellen und kontextuellen Eigenschaften eines Textes. In diesem Abschnitt zeige ich Ihnen, welche Arten von Signalen Large Language Models besonders gut erkennen und wie Sie diese gezielt einsetzen können, um die Sichtbarkeit und Einordnung Ihrer Inhalte zu verbessern.
Semantische Klarheit
Strukturierte Sprache und klare Konzepte
LLMs bevorzugen Inhalte, die klare, eindeutig verständliche Aussagen treffen. Dazu gehört die Verwendung etablierter Begriffe, eine verständliche Satzstruktur und die konsequente Nutzung definierter Konzepte. Unklare Metaphern, verworrene Formulierungen oder stilistische Umwege schwächen die semantische Signalstärke eines Textes.
Nutzung von Standardterminologie
Je häufiger ein Begriff in Trainingsdaten in einem bestimmten Zusammenhang verwendet wurde, desto stabiler ist seine semantische Einordnung. Deshalb sollten Sie bei der Erstellung von Inhalten auf branchenübliche oder fachlich etablierte Begriffe zurückgreifen, statt eigene Begriffe oder Marketingformulierungen zu erfinden, es sei denn, diese sind explizit definiert und kontextualisiert.
Kontextuelle Tiefe
Einbettung in Themenlandschaften
LLMs erkennen, ob ein Inhalt „für sich allein steht“ oder in eine breitere inhaltliche Struktur eingebettet ist. Inhalte, die mit verwandten Themen, relevanten Quellen oder anerkannten Konzepten verknüpft sind, wirken glaubwürdiger und informativer. Sowohl für Menschen als auch für Maschinen.
Referenzrahmen und Relationen
Die Einordnung eines Inhalts erfolgt über semantische Nähe im Vektorraum. Je stärker Sie durch interne Verlinkungen, Vergleiche, Quellenangaben oder explizite Bezugnahmen thematische Zusammenhänge herstellen, desto klarer ist Ihre Positionierung im Modell. LLMs nutzen solche Relationen, um Bedeutungsketten zu konstruieren.
Formatierung und technische Struktur
Überschriften, Listen, semantisches HTML
Auch wenn LLMs Textinhalte „entstrukturieren“, bevor sie in Vektoren übersetzt werden, hilft eine technisch saubere Formatierung dabei, die Gewichtung von Abschnitten zu steuern. Semantische HTML-Tags (h2, h3, strong, etc.) geben Hinweise auf inhaltliche Relevanz, Argumentationsstruktur und Themenhierarchie.
Strukturierte Daten und Metainformationen
Die Nutzung von JSON-LD, Schema.org, Open Graph Tags oder anderen standardisierten Metadaten erhöht nicht nur die Sichtbarkeit in klassischen Suchsystemen, sondern gibt auch zusätzliche Signale, die von LLMs genutzt werden können – etwa zur Einordnung von Entitäten, Kategorien oder Autorenrollen.
Ein Beispiel unserer Strukturierten Daten (JSON-LD) für unsere Startseite
{
"@context": "https://schema.org",
"@graph": [
{
"@type": "Place",
"@id": "https://cyber-sour.com/#place",
"geo": {
"@type": "GeoCoordinates",
"latitude": "51.3573655658016",
"longitude": " 12.416305168808046"
},
"hasMap": "https://www.google.com/maps/search/?api=1&query=51.3573655658016, 12.416305168808046",
"address": {
"@type": "PostalAddress",
"streetAddress": "Gorkistraße 48",
"addressLocality": "Leipzig",
"addressRegion": "Sachsen",
"postalCode": "04347",
"addressCountry": "DE"
}
},
{
"@type": "Organization",
"@id": "https://cyber-sour.com/#organization",
"name": "Cyber Sour",
"url": "https://cyber-sour.com/",
"sameAs": [
"https://www.facebook.com/people/CyberSour/100089217550857/",
"https://www.instagram.com/cyber.sour.online/",
"https://www.linkedin.com/company/99507043/admin/feed/posts/?feedType=following",
"https://www.tiktok.com/@cybersour.online"
],
"email": "info@cyber-sour.com",
"address": {
"@type": "PostalAddress",
"streetAddress": "Gorkistraße 48",
"addressLocality": "Leipzig",
"addressRegion": "Sachsen",
"postalCode": "04347",
"addressCountry": "DE"
... und so weiter
Wiedererkennbare Muster
Begriffskombinationen und Co-Occurrence
LLMs erkennen, wenn bestimmte Begriffe regelmäßig gemeinsam auftreten – etwa in Fachartikeln oder wissenschaftlichen Publikationen. Durch bewusste Wiederholung solcher Kombinationen innerhalb eines Themas signalisieren Sie dem Modell, dass Ihre Inhalte zur typischen Verwendung dieses Kontexts gehören.
Verlinkungen und zitierte Quellen
Externe Verweise auf anerkannte Quellen sowie interne Verlinkungen auf konsistente Themencluster erhöhen die semantische Dichte. Sie schaffen Vertrauen und Kontextualisierung – beides Elemente, die LLMs stärker gewichten als z. B. reine Keyword-Platzierungen.
Quellen:
OpenAI Research Reports: https://openai.com/research
Google Search Central: https://developers.google.com/search/docs
Checkliste: So stärken Sie gezielt Ihre Content-Signale für LLMs
Semantische Klarheit
Ziel: Eindeutige Sprache und fachlich korrekte Begriffe
Fragen zur Selbstprüfung:
- Verwende ich eindeutige Begriffe, die fachlich etabliert sind?
- Verzichte ich auf Doppeldeutigkeiten oder Marketing-Slang?
- Habe ich zentrale Begriffe im Text mehrfach in konsistentem Kontext eingebunden?
- Wird klar, worum es geht – auch ohne visuelle Unterstützung?
Kontextuelle Tiefe
Ziel: Thematische Einbettung und semantische Verbindung
Fragen zur Selbstprüfung:
- Ist der Text thematisch mit anderen relevanten Inhalten verlinkt?
- Gibt es Hinweise auf verwandte Konzepte, Kategorien oder Entitäten?
- Nenne ich Quellen oder Fachbeiträge, die das Thema einordnen?
- Wird deutlich, wie mein Inhalt in den größeren thematischen Rahmen passt?
Formatierung & technische Struktur
Ziel: Technisch saubere Darstellung und klare Hierarchien
Fragen zur Selbstprüfung:
- Verwende ich semantisches HTML (tags wie <h2>, <strong>, etc.)?
- Sind Absätze logisch gegliedert und nicht zu lang?
- Nutze ich strukturierte Daten (z. B. Schema.org, JSON-LD)?
- Sind Titel, Meta-Angaben und Inhaltsstruktur konsistent?
Wiedererkennbare Muster
Ziel: Fachtypische Begriffskombinationen und Quellenverweise
Fragen zur Selbstprüfung:
- Tauchen Begriffe im typischen thematischen Zusammenhang auf?
- Verwende ich häufig gemeinsam genutzte Fachbegriffe und Synonyme?
- Habe ich relevante externe Quellen oder Normen verlinkt?
- Ist mein Text anschlussfähig an gängige fachliche oder wissenschaftliche Inhalte?
Wie LLMs Inhalte crawlen und klassifizieren
Was mit Ihrem Inhalt passiert, bevor er zur Antwort wird
Damit ein Text von einem LLM genutzt werden kann, muss er zunächst erfasst, verarbeitet und intern repräsentiert werden. In diesem Abschnitt zeige ich Ihnen, wie Sprachmodelle Inhalte überhaupt „sehen“, welche technischen Phasen dabei eine Rolle spielen und welche Signale besonders stark wirken.
Training und Inferenz: Zwei getrennte Phasen der Verarbeitung
Trainingsphase: Lernen durch Datenmengen
In der Trainingsphase wird das Modell mit riesigen Mengen an Textdaten gespeist. Dabei lernt es, sprachliche Muster und semantische Beziehungen zu erkennen – durch Wahrscheinlichkeitsverteilungen, nicht durch Regeln oder explizites Wissen.
Inferenzphase: Antworten aus Gelerntem
In der Inferenzphase (der eigentlichen Nutzung nach dem Training) wird das Modell nicht mehr neu „gefüttert“. Stattdessen generiert es auf Basis der gelernten Repräsentationen Antworten auf konkrete Eingaben.
Hinweis für Unternehmen:
Inhalte, die nicht während des Trainings im Datensatz enthalten waren, müssen über API-Zugänge, Plugins oder Retrieval-Systeme integriert werden – ansonsten können sie vom Modell nicht direkt genutzt werden.
Embeddings: Die semantische Kartierung von Inhalten
Ein zentraler Mechanismus in der Verarbeitung durch LLMs ist das sogenannte Embedding. Dabei wird jeder Text oder jedes Wort als Vektor in einem mehrdimensionalen Raum dargestellt. Inhalte, die thematisch ähnlich sind, liegen in diesem Raum nah beieinander – auch wenn sie sprachlich unterschiedlich formuliert sind.
Das bedeutet: Ein Inhalt mit sauberem Signaling erzeugt eine präzise Positionierung im Vektorraum. Diese Position bestimmt mit, ob das Modell den Text als passend, vertrauenswürdig oder relevant einstuft, etwa bei der Beantwortung einer konkreten Nutzeranfrage.
Beispiel:
Wenn Ihr Unternehmen Begriffe wie „Photovoltaik“, „Wechselrichter“, „Solarspeicher“ und „Netzeinspeisung“ häufig in sinnvollen Kontexten verwendet, wird es in der Embedding-Struktur als „kompetente Quelle für PV-Technik“ wahrgenommen.
Implizite und explizite Signale
LLMs erkennen sowohl explizite Signale (z. B. durch strukturierte Daten, Autorenangaben oder Domain Authority) als auch implizite Signale (z. B. durch konsistente Sprache, semantische Dichte, zitierte Quellen).
Je besser ein Inhalt in beide Signalformen investiert, desto robuster ist seine spätere Nutzung im Modell – sei es durch direktes Zitieren, Paraphrasieren oder die Verwendung als thematische Referenz.
Quelle:
Hugging Face Blog: https://huggingface.co/blog
Best Practices für Content, der LLM-freundlich ist
Wie Sie Inhalte gestalten, die LLMs erkennen, einordnen und verwenden
In diesem Abschnitt zeige ich Ihnen konkrete Maßnahmen, mit denen Sie Ihre Inhalte so aufbereiten, dass sie von Sprachmodellen effizient erfasst, korrekt interpretiert und kontextstabil eingebettet werden. Dabei geht es um technische, sprachliche und strukturelle Prinzipien – basierend auf aktuellen Erkenntnissen aus Forschung, SEO und KI-Praxis.
Klare semantische Struktur
Verwenden Sie saubere und semantisch korrekte HTML-Strukturen
Achten Sie auf eine konsistente Verwendung von HTML Tags (<h2>, <h3>, <strong>, <blockquote>, etc.), um logische Hierarchien im Text sichtbar zu machen. Das hilft nicht nur Nutzern, sondern auch LLMs, den Aufbau und die Argumentation Ihres Inhalts nachzuvollziehen.
Strukturieren Sie Inhalte mit Absätzen, Listen und Gliederungen
Kurze, klar getrennte Absätze, nummerierte Listen, Zwischenüberschriften und eindeutige Titel verbessern die Verarbeitbarkeit des Textes. Besonders bei langen Beiträgen ist das entscheidend für die semantische Erfassung.
Verwendung etablierter Begriffe und Kontexte
Setzen Sie auf terminologische Konsistenz
Verwenden Sie Fachbegriffe in der gleichen Form wie sie in Ihrer Branche üblich sind – und halten Sie diese Konsistenz über alle Inhalte hinweg ein. Das erhöht die Wahrscheinlichkeit, dass LLMs Ihre Inhalte korrekt clustern.
Vermeiden Sie semantisches Rauschen
Texte mit zu viel werblicher Sprache, Metaphern oder unklaren Formulierungen senden schwache oder irreführende Signale. Bleiben Sie präzise, sachlich und fokussiert – besonders in den Kernabschnitten Ihrer Inhalte.
Langfristige Content-Hygiene
Aktualisieren Sie Inhalte regelmäßig
Veraltete Informationen können zu Fehlinterpretationen durch Sprachmodelle führen, vor allem wenn sie mit aktuellen Daten konkurrieren. Aktualisieren Sie wichtige Beiträge regelmäßig, und verwenden Sie Datumshinweise oder Versionsvermerke.
Achten Sie auf Konsistenz im Gesamtauftritt
LLMs „lesen“ nicht nur einzelne Seiten, sondern ziehen Signale aus der Gesamtstruktur Ihrer Domain. Einheitliche Sprache, wiedererkennbare Formatierung und kontextstarke interne Verlinkungen stärken Ihre Position als zuverlässige Quelle.
Setzen Sie auf EEAT-Signale
Der von Google etablierte EEAT-Standard (Experience, Expertise, Authoritativeness, Trustworthiness) ist auch für LLMs von Bedeutung – selbst wenn nicht direkt messbar.
Praktische Hinweise:
- Weisen Sie Autoren und Expertise aus (z. B. in Autorenboxen)
- Verlinken Sie auf hochwertige Quellen und Fachbeiträge
- Machen Sie klar, warum Ihr Unternehmen über Erfahrung zu einem Thema verfügt
- Verwenden Sie strukturierte Daten zur Auszeichnung von Autor, Organisation, Bewertungen etc.
Quelle:
Moz Blog: https://moz.com/blog
Risiken bei fehlendem oder irreführendem Signaling
Warum unklare oder fehlerhafte Inhalte für LLMs problematisch sind
Nicht nur die Präsenz, sondern auch die Qualität der Signale entscheidet darüber, wie ein Sprachmodell Inhalte einordnet. In diesem Abschnitt zeige ich Ihnen, welche konkreten Risiken entstehen können, wenn Inhalte kein oder ein falsches Content Signaling aussenden und warum das langfristig Relevanz und Vertrauenswürdigkeit gefährdet.
Halluzinationen durch fehlende Signale
Wenn ein LLM auf eine Eingabe keine klaren, kontextstarken Inhalte im eigenen Wissensraum findet, besteht die Gefahr sogenannter Halluzinationen. Das bedeutet: Das Modell erzeugt Antworten, die falsch, erfunden oder irreführend sind weil keine belastbaren Ankerpunkte vorhanden sind.
Diese Gefahr ist besonders groß, wenn:
- Inhalte zu selten oder widersprüchlich auftreten
- keine Quellen- oder Autorsignale vorhanden sind
- der Text sich nicht eindeutig einem Themenfeld zuordnen lässt
In der Praxis führt das dazu, dass Ihr Unternehmen bei bestimmten Themen entweder gar nicht berücksichtigt oder falsch dargestellt wird.
Fehlzuordnungen im semantischen Raum
Ein weiterer Risikofaktor liegt in der falschen Einbettung im Vektorraum. Inhalte, die unscharf formuliert sind oder inkonsistente Begriffe verwenden, können inhaltlich falschen Clustern zugeordnet werden.
Beispiel:
Ein Beitrag über nachhaltige Energie, der gleichzeitig Begriffe aus Lifestyle-Marketing, Finanzberatung und Mobilität vermischt, kann vom Modell falsch klassifiziert werden – etwa als Werbetext, statt als technische Quelle.
Das Resultat:
Der Text wird von LLMs nicht mehr als thematisch verlässlich eingestuft – und erscheint bei komplexeren Prompts schlicht nicht mehr.
Verlust von Autorität und Vertrauenssignalen
Sprachmodelle bewerten nicht nur Inhalte, sondern auch implizit deren Quelle. Wenn eine Website inkonsistente Signale sendet, z. B. durch fehlende Autorenschaft, widersprüchliche Aussagen oder mangelnde Kontextvernetzung, sinkt die Wahrscheinlichkeit, dass Inhalte des Anbieters in Modellen als autoritativ behandelt werden.
Das betrifft nicht nur einzelne Seiten, sondern oft ganze Domains. Besonders kritisch ist dies für:
- medizinische, technische oder juristische Themen
- erklärende Inhalte mit öffentlicher Wirkung
- Themen mit hohem Risiko für Fehlinterpretation
Quelle:
NIST AI Risk Management Framework: https://www.nist.gov/itl/ai-risk-management-framework
Strategische Nutzung von Content Signaling in SEO und Knowledge Graphs
Verbindung zu Entity SEO, Topic Maps und strukturiertem Wissen
LLMs greifen beim Verstehen und Einordnen von Inhalten nicht nur auf sprachliche Muster zurück, sondern vernetzen Informationen kontextuell über Entitäten, also klar definierte, wiedererkennbare „Wissensobjekte“ wie Personen, Marken oder Orte. Damit Inhalte in solchen Netzwerken auftauchen und zuverlässig zugeordnet werden, ist eine saubere semantische Strukturierung notwendig.
Entity SEO zielt genau darauf ab: Inhalte so aufzubereiten, dass sie klar einer Entität zugewiesen werden können. Wer in Wikipedia auftaucht oder in einer Topic Map (Themenlandkarte) referenziert ist, hat deutlich bessere Chancen, von LLMs als vertrauenswürdige Quelle erkannt zu werden.
Aufbau eines digitalen Autorenprofils (Author Entity)
Ein starker Author Signal ist nicht nur für Google (EEAT) von Relevanz, sondern auch für LLMs. Inhalte, die wiederholt mit einem bestimmten Autorennamen, Expertengebiet und eindeutiger Urheberschaft auftreten, werden mit höherem Vertrauen behandelt.
Ein konsistentes digitales Autorenprofil sollte daher:
- regelmäßig gepflegt (z. B. auf LinkedIn, GitHub, Fachportalen)
- semantisch referenziert (z. B. per sameAs in JSON-LD)
- inhaltlich fokussiert sein
LLMs aggregieren über Millionen von Inhalten. Ein stimmiges, wiedererkennbares Muster des Autors steigert die Wahrscheinlichkeit, als glaubwürdige Quelle in Antworten aufzutauchen.
Structured Content als API-fähiger Informationsraum
Zunehmend agieren LLMs nicht mehr nur als Textgeneratoren, sondern als Schnittstelle zur strukturierten Wissensabfrage. Inhalte, die über semantische Markup-Standards (z. B. Schema.org) oder offene APIs bereitgestellt werden, bilden die Grundlage für solche Abfragen.
Beispiel:
Ein Anbieter von Finanzprodukten kann statt einer allgemeinen Leistungsbeschreibung eine klar strukturierte JSON-LD-Dokumentation bereitstellen. Diese Informationen sind maschinenlesbar, leicht indexierbar und können von LLMs direkt für strukturierte Antworten, Tabellen oder Abfragen verwendet werden. Ohne Umweg über Fließtext.
Quellen:
Kalicube, Entity SEO: https://kalicube.com/entity/entity-seo/
Wordlift Blog: https://wordlift.io/blog/en/
Ausblick: Content-Architektur für eine LLM-gesteuerte Zukunft
Warum das klassische SEO-Paradigma nicht mehr ausreicht
Die Grundprinzipien klassischer Suchmaschinenoptimierung basieren auf Ranking, Klickverhalten und organischer Sichtbarkeit. LLMs funktionieren anders: Sie benötigen Inhalte, die nicht nur sichtbar, sondern strukturell verlässlich und semantisch präzise sind.
In diesem Beitrag habe ich Ihnen gezeigt, wie Content Signaling funktioniert. Der Ausblick geht jedoch noch weiter: Unternehmen, die in LLMs langfristig vorkommen und bestehen wollen, müssen Inhalte als strukturierte Wissensbausteine denken, nicht nur als Textseiten mit Keywords.
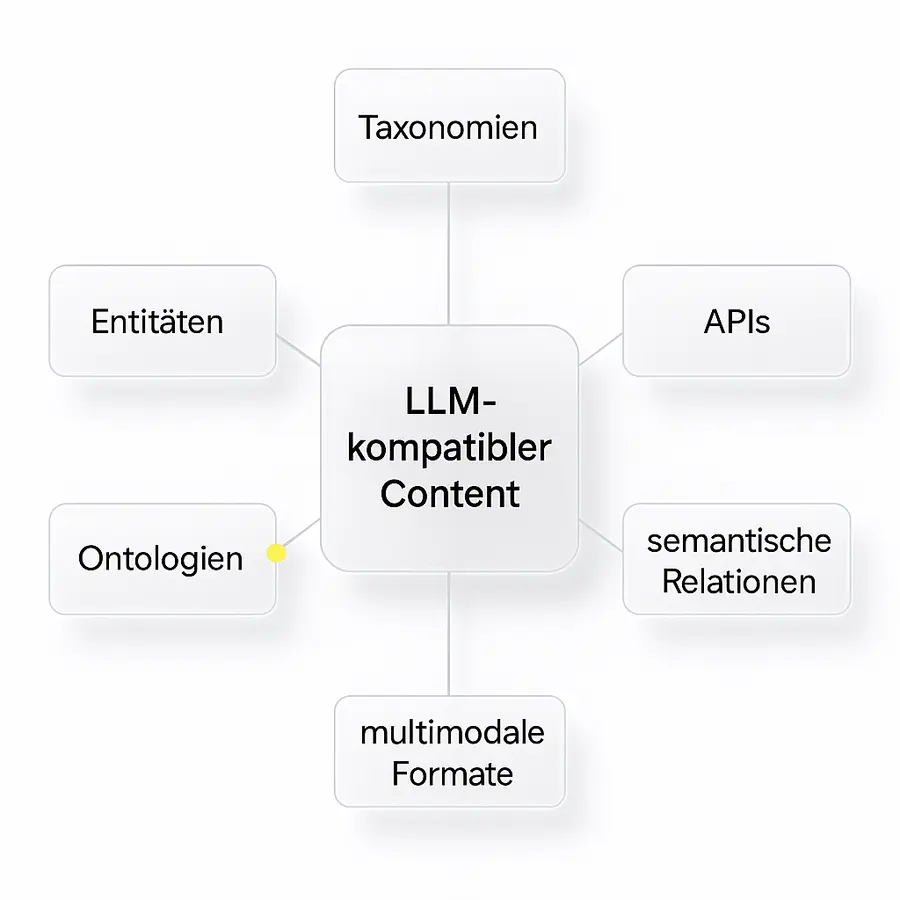
Content als Input für LLMs: Taxonomien, APIs, semantische Knoten
Der Übergang zur LLM-gesteuerten Verarbeitung bedeutet, dass Inhalte zunehmend als strukturierte Einheiten aufgerufen werden, oft über Schnittstellen (APIs), Datenfeeds oder Wissensdatenbanken.
Drei Schlüsselkonzepte:
- Taxonomien: Inhalte werden klaren Themenfeldern, Entitäten und Kategorien zugeordnet
- APIs: Unternehmen stellen eigene Daten über Schnittstellen bereit, die LLMs aktiv abfragen oder indexieren können
- Semantische Knoten: Inhalte werden mit bestehenden Wissensnetzen verknüpft – z. B. durch Verlinkungen auf Wikipedia, Wikidata, Open Source Glossare oder öffentlich dokumentierte Strukturen
So entsteht ein „Content-Ökosystem“, das nicht auf Sichtbarkeit, sondern auf maschinelle Nutzbarkeit ausgelegt ist.
Vorbereitung auf multimodale Modelle
Die nächste Generation von LLMs ist nicht mehr auf Text beschränkt. Modelle wie DeepMind Gemini, GPT-4o oder Claude 3 verarbeiten Bilder, Audiodaten, Videos und strukturierte Inputs gleichzeitig.
Unternehmen müssen deshalb in der Lage sein, Inhalte:
- modular aufzubereiten (Text, Bild, Daten getrennt, aber verknüpft)
- kontextübergreifend bereitzustellen (z. B. durch Alt-Texte, Transkripte, strukturierte Audioinformationen)
- für multimodale Interpretation maschinenlesbar zu machen
Das betrifft nicht nur den Content selbst, sondern auch den Aufbau der Content-Architektur im Backend: Vom CMS über die API bis zur semantischen Modellierung.
Quellen:
DeepMind Gemini: https://deepmind.google/research/publications/157741/
OpenAI Blog: https://openai.com/blog
Fazit
In diesem Beitrag habe ich Ihnen gezeigt, dass Large Language Models Inhalte nicht wie klassische Suchmaschinen verarbeiten. Sie sind keine Crawler mit einem statischen Index, sondern dynamische Modelle, die Texte semantisch einordnen, gewichten und reproduzieren. Wer heute mit seinen Inhalten in LLMs sichtbar sein will, muss diese Systeme verstehen und strategisch mit Content Signaling arbeiten. Dazu gehören nicht nur strukturelle Maßnahmen wie semantische Markup-Strategien, sondern auch eine neue redaktionelle Haltung, die Klarheit, Kontexttiefe und Relevanz in den Mittelpunkt stellt.
Praktische Relevanz für Unternehmen, Autoren und SEO-Teams
Für Unternehmen bedeutet das: Sichtbarkeit in LLMs beginnt nicht mit klassischen Keywords, sondern mit sinnvoll strukturierten, thematisch kohärenten Inhalten, die über APIs, Sitemaps oder standardisierte Formate abrufbar sind. Für Autoren und SEO-Teams heißt es: Mehr Kontext, weniger Tricks. Je klarer ein Thema erschlossen, vernetzt und formuliert ist, desto höher die Chance, in LLM-generierten Antworten berücksichtigt zu werden, ganz gleich, ob im Assistenzsystem, Chatbot oder KI-gestütztem Interface.
Handlungsimpulse für die Content-Praxis
- Entwickeln Sie Inhalte entlang semantischer Achsen statt rein nach Suchvolumen.
- Nutzen Sie technische Standards wie schema.org, um maschinenlesbare Strukturen zu erzeugen.
- Pflegen Sie Schnittstellen: Content sollte maschinenverfügbar und modular abrufbar sein.
- Verknüpfen Sie Inhalte intern und extern – semantische Netze erhöhen die Sichtbarkeit in LLMs.
- Testen Sie regelmäßig: Welche Inhalte werden in KI-Antworten tatsächlich erwähnt oder zitiert?